Hace tiempo que no escribía unas líneas en el blog por diversos temas personales, pero qué mejor forma de reanudar los artículos que contando cómo podemos ayudar en lo que tristemente se ha convertido en una crisis mundial: la pandemia del coronavirus COVID-19.
Azure, como otras plataformas de cloud público, puede jugar un papel relevante en la crisis, permitiendo desplegar infraestructura de escalabilidad masiva para el hospedaje de aplicaciones o servicios orientados a facilitar el trabajo y la comunicación de todas las personas que están dando el máximo: profesionales sanitarios, cuerpos y fuerzas de seguridad, transportistas, empleados de supermercados, la comunidad científica...
Precisamente en este artículo quería hablar de cómo podemos colaborar con la comunidad científica que esta estudiando formas de combatir la epidemia, algo surgió después de ver este tweet...
...y tras tener una conversación interesante con varios artistas del sector Azure como Carlos Mendible -que se lanzó inmediantamente a contenerizar FAHClient- o David Rodríguez. ¡La pipol de la comunidad moláis y lo sabéis!
Un viejo conocido: el proyecto Folding@home
Conocí el proyecto Folding@home hace ya más de 10 años a través de Antonio López Márquez, en nuestra etapa como investigadores en la Universidad de Almería. Se trata de un proyecto de computación distribuida para simular dinámicas de proteínas, incluyendo los procesos de plegado y movimiento implicados en un número notable de enfermedades. Cualquier persona con un PC doméstico puede donar ciclos de su CPU y GPU a la comunidad científica y ayudar así en la computación de cálculos tan complejos. Seguro que a muchos les está recordando al proyecto SETI@home, con una arquitectura similar, pero enfocado en la búsqueda de vida inteligente a través de señales captadas por radiotelescopios.
El proyecto -que normalmente trabaja en cargas computacionales orientadas a investigaciones sobre el cáncer, Alzheimer, Parkison o Huntington- ha recibido muchísimas para simulaciones relacionadas con el COVID-19, que tienen como objetivo encontrar en el virus una diana terapéutica que nos permita atacarlo mediante fármacos o anticuerpos sin dañar los tejidos y células de nuestro propio organismo.
¿Quién está detrás de Folding@home?
Un buen número de laboratorios de investigación a lo largo de todo el planeta, entre los que se encuentran:
- BOWMAN LAB,WASHINGTON UNIVERSITY IN ST. LOUIS
- CHODERA LAB, MEMORIAL SLOAN-KETTERING CANCER CENTER
- VOELZ LAB, TEMPLE UNIVERSITY
- HUANG LAB, HKUST
- IZAGUIRRE LAB, NOTRE DAME
- KASSON LAB, UNIVERSITY OF VIRGINIA
- LINDAHL LAB, STOCKHOLM UNIVERSITY
- SHIRTS LAB, UNIVERSITY OF VIRGINIA
- SNOW LAB, COLORADO STATE UNIVERSITY
- SORIN LAB, CSULB
- ZAGROVIC LAB, MEDITERRANEAN INSTITUTE FOR LIFE SCIENCES
Además, el proyecto ha contado con el patrocinio de conocidas empresas del sector tecnológico:
- Intel (2001-2002)
- Google (2001-2003)
- Sony (2005-2012, 2014-2016)
- ATI, AMD (2005 - actualidad)
- NVIDIA (2007 - actualidad)
Dicho sea de paso, servidor no tiene ninguna afiliación ni relación con el proyecto.
¿Puedo ver la lista de investigaciones en las que están trabajando? ¿Cuántas de ellas son relacionadas con el COVID-19?
Hay un listado completo aquí, con cargas de trabajo tanto para CPU como para GPU (a través de CUDA y OpenCL.
Los proyectos sobre el COVID-19 son:
- CPU: 14328, 14329, 14530, 14531
- GPU: del 11741 al 11764
¿Cómo puedo donar capacidad de cómputo de mi PC local para luchar contra el COVID19?
¡En dos pasos muy sencillos!
- Ve con tu navegador a la URL https://foldingathome.org/start-folding/ y descarga el cliente para tu sistema operativo. Están soportados Windows, macOS y GNU/Linux, en arquitecturas x86 y x86_64.
- Después de instalarlo selecciona como TARGET la opción
ANY. Esto prioriza automáticamente las cargas de trabajo relacionadas con el COVID-19.
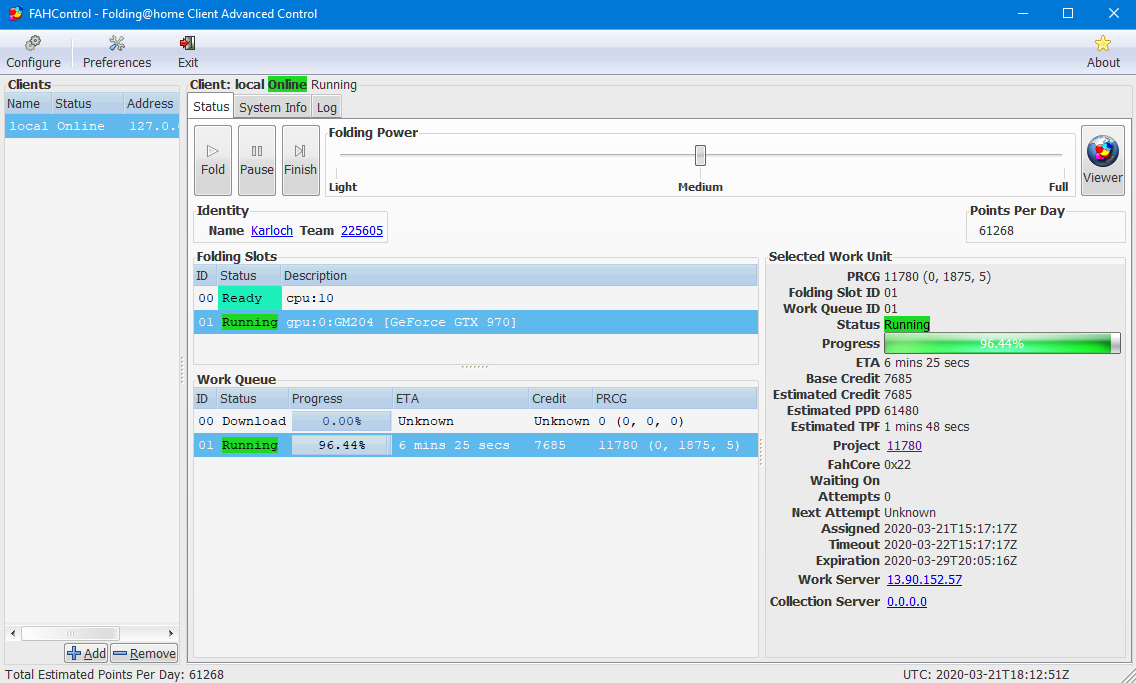
Esta es una captura de pantalla del cliente funcionando en mi estación de trabajo con una carga para GPU:
Folding@home en Microsoft Azure
No sólo podemos ejecutar Folding@home en nuestro equipo de escritorio o servidor doméstico, sino que también podemos hacerlo en Azure y las máquinas virtuales con GPU tienen mucho que aportar en ese sentido.
No voy a entrar en cómo instalar el cliente de Folding@home -de ahora en adelante FAHClient- en una máquina virtual por lo obvio de la situación. Sin embargo, he preparado un repositorio de Github con todo lo necesario para ejecutarlo con Docker, Kubernetes, Azure Kubernetes Service o Azure Container Instances. Para ello incluye:
- Un Dockerfile que prepara la imagen Docker con el FAHClient.
- Un par de plantilas de Azure Resource Manager para desplegar desde 0 un cluster de Azure Kubernetes Service o bien Azure Container Instances.
- Un par de manifiestos de Kubernetes en YAML para instalar los drivers gráficos de NVIDIA en los nodos de Kubernetes y -por supuesto- desplegar FAHClient.
- Un par de scripts GNU bash que ayuda a la implementación del cluster de AKS, por ejemplo, creando el Azure AD Service Principal asociado.
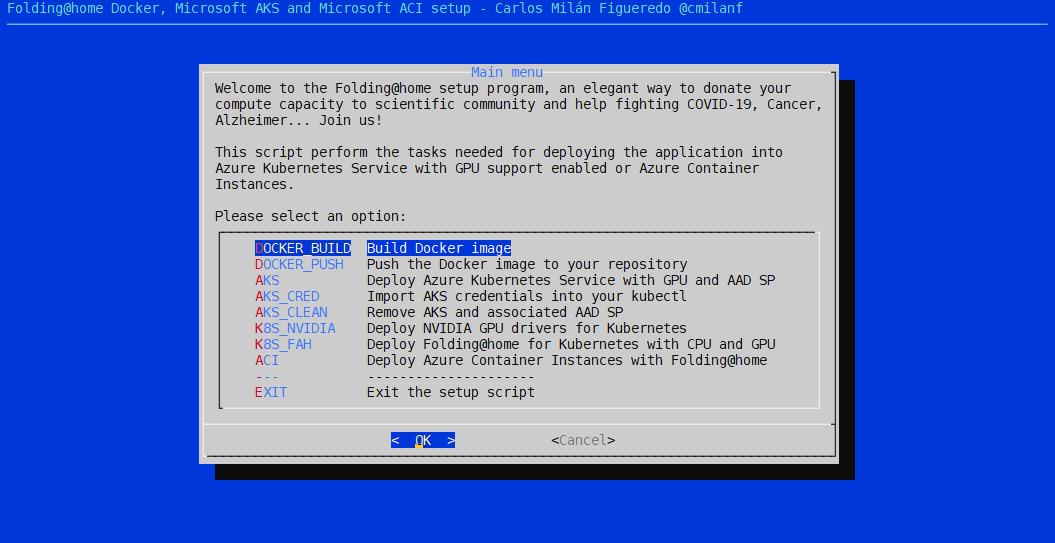
- Un script que implementa una interfaz de usuario en modo texto para hacer el despliegue de todo lo comentado rápido y ameno.
Veamos cada uno con un pelín de detalle.
Dockerfile
Lo más reseñable del Dockerfile es que nos basamos en la imagen de nvidia/opencl. Esto es muy importante para poder habilitar el soporte GPU, ya que incorpora las bibliotecas de CUDA y OpenCL que la aplicación va a necesitar.
Además de eso merece la pena comentar el RUN:
RUN apt-get update \
&& apt-get -y install --no-install-recommends wget \
&& wget --no-check-certificate -O /tmp/fahclient.deb ${FAHCLIENT_DOWNLOAD_URL} \
&& dpkg --unpack /tmp/fahclient.deb \
&& rm -f /var/lib/dpkg/info/fahclient.postinst \
&& dpkg --configure fahclient \
&& apt-get install -yf \
&& rm -f /tmp/fahclient.deb
Se puede ver como no instalo el paquete DEB mediante un clásico dpkg -i y en su lugar lo descompongo en varios pasos, eliminando el script de post-instalación fahclient.postinst. ¿Por qué? Tiene un problema que le impide funcionar en algunas distribuciones de GNU/Linux, entre ellas el Ubuntu en el que esta basado la imagen de NVIDIA. Como el script de post-instalación sólo realiza tareas para agregar el cliente al init.d, no es algo que nos importe mucho en una imagen Docker.
Por último, el ENTRYPOINT es el binario del FAHClinet y el CMD sus parámetros, ya que queremos darle al usuario o administrador de sistemas la facilidad de cambiarlos según sus necesidades.
ENTRYPOINT ["/usr/bin/FAHClient"]
CMD ["--user=Anonymous", "--team=0", "--gpu=false", "--smp=true", "--power=full"]
Esto va a ser de mucha importancia porque FAHClient no hace honor a los namespaces del kernel de Linux, una situación que ya ocurría con la máquina virtual de Java en versiones anteriores a la 1.10. ¿Y por qué es importante? Porque a FAHClient le vamos a poder facilitar por parámetro cual es la cantidad de memoria y el número de CPUs reales que tiene permitido utilizar.
Ya daba una pista en el label usage_advanced:
usage_advanced="docker run -it -m <memory limit in bytes> --cpus <number of cpus to use> --rm cmilanf/fahclient --user=<username> --team=<team number> --gpu=<true or false> --smp=<true or false> --power=<light, medium or full> --cpus <number of cpus to use> --memory=<memory usage in bytes> --cause=ANY"
El repositorio de Github está enlazado con el de Docker, por lo que hay siempre una build de la imagen lista para utilizar. Eso quiere decir que os podéis ahorrar construir vuestra propia imagen y subirla a un repositorio si no lo véis necesario.
Plantilla ARM para AKS: deploy-gpu-aks.json
Es una plantilla preparada para desplegar clusters de AKS con muchas de las características que puede tener: node pools, VMSS, kubenet/Azure CNI, VNET existente o no, RBAC, ACR...
Quizá merezca más la pena echar un vistazo al archivo deploy-gpu-aks.parameters.json donde de un vistazo rápido podemos ver las opciones de configuración que podemos modificar según queramos. Por defecto lo hacemos de la siguiente manera:
- Nueva VNET, vamos a hacer una implementación aislada porque no tenemos ninguna necesidad de que FAHClient se hable con nada.
- Modelo de networking kubenet (que Azure llama básico). Una vez, más, no tenemos necesidad de utilizar las características de Azure CNI.
- Los valores del Azure AD Service Principal serán completados automáticamente por el script.
- Como máquinas virtuales vamos a usar la serie NC6, que son considerablemente más baratas en la región de North Europe que en West Europe, y además tenemos por ahora disponibles la edición
Standard_NC6_Promoque nos da un precio todavía mejor. - No creamos Azure Container Registry porque la imagen la retiramos de Docker Hub
¡Vamos a la versión ACI!
Plantilla ARM para ACI: deploy-aci.json
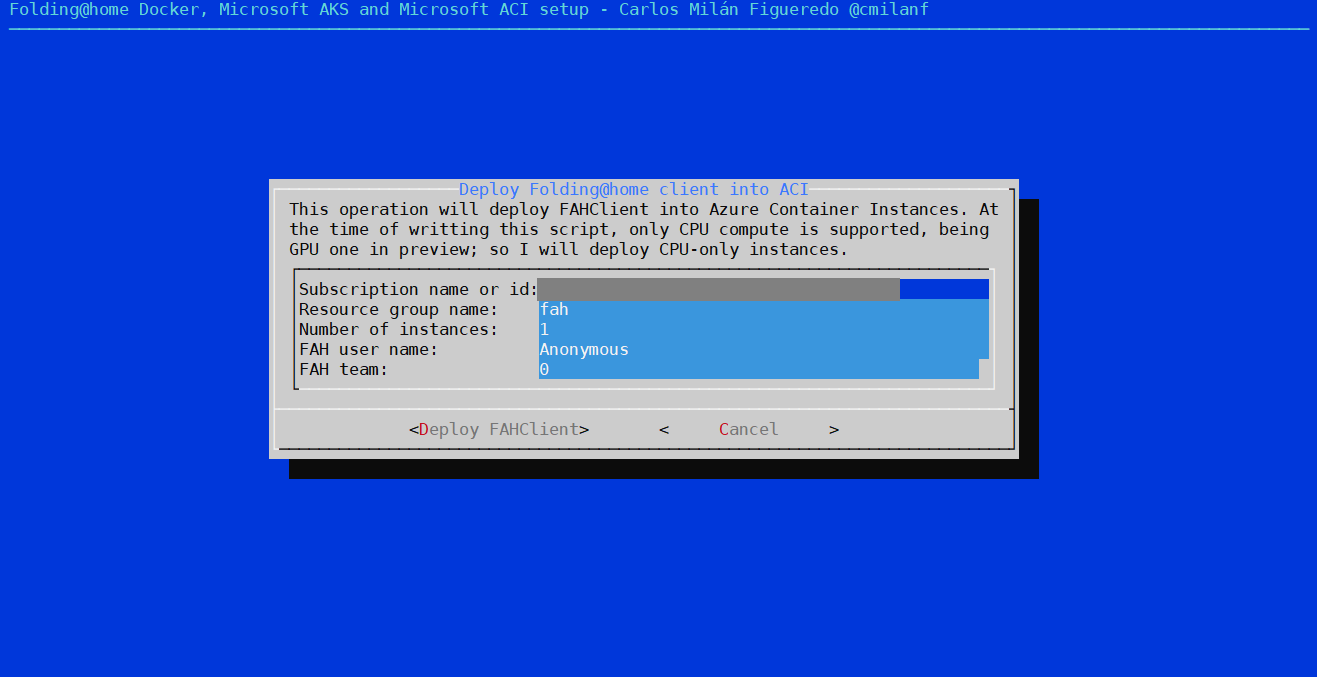
Mucho más sencilla que la de AKS, pero a diferencia del anterior, el soporte GPU en ACI se encuentra en preview en el momento de escribir estas líneas.
Aún así podemos utilizar ACI para los proyectos con cargas de trabajo para CPU y la plantilla está preparada para desplegar cuantas instancias le solicitemos.
Manifiestos Kubernetes: nvidia-device-plugin-ds.yaml
Reconozco que me costó un poco comprender el funcionamiento de este plugin, pero en el fondo tiene mucho sentido. Este manifiesto nos permite habilitar el acceso a la GPU desde los pods de nuestro cluster, convirtiéndola en un recurso más del nodo (como lo es la RAM o la CPU), que podemos solicitar. Se implementa mediante un DaemonSet que básicamente procura que una copia del pod en cuestión se ejecuta en cada nodo.
¿Y qué es lo que hace este pod? Expone los controladores de GPU ya instalados previamente en el nodo a nuestros pods mediante un volume. Y si en AKS no gestionamos los nodos, ¿quien ha instalado esos controladores? Efectivamente, cumpliendo con lo que se espera de un PaaS: Microsoft. Nosotros no tenemos que hacer nada en el nodo en cuestión, están ya instalados y aplicando este manifiesto se exponen a nuestros pods.
Tras ello una sencilla operación de kubectl describe node debería revelarnos que tenemos un nuevo recurso llamado nvidia.com/gpu disponible.

Manifiestos Kubernetes: fah-deployment.yaml
Este manifiesto de Kubernetes despliega la aplicación. Merece la pena que lo cite entero para hablar de él:
apiVersion: apps/v1
kind: Deployment
metadata:
name: fahclient
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: fahclient
strategy:
type: Recreate
template:
metadata:
labels:
app.kubernetes.io/name: fahclient
spec:
nodeSelector:
'kubernetes.io/os': linux
containers:
- image: cmilanf/fahclient:latest
imagePullPolicy: Always
name: fahclient
env:
- name: CAUSE
value: ANY
- name: FAH_USER
value: Anonymous
- name: FAH_TEAM
value: '0'
- name: USE_GPU
value: 'true'
- name: USE_SMP
value: 'true'
- name: POWER
value: full
- name: CPUS
value: '5'
- name: MEM
value: '2147483648'
command: ["/usr/bin/FAHClient"]
args: ["--user=$(FAH_USER)", "--team=$(FAH_TEAM)", "--gpu=$(USE_GPU)", "--smp=$(USE_SMP)", "--power=$(POWER)",
"--memory=$(MEM)", "--cpus=$(CPUS)", "--cause=$(CAUSE)"]
resources:
requests:
memory: 512Mi
cpu: 1000m
nvidia.com/gpu: 1
limits:
memory: 2048Mi
cpu: 5000m
nvidia.com/gpu: 1
Lo que más llama la atención es que los parámetros de la ejecución del cliente los podemos definir mediante la declaración de variables de entorno. Como he mencionado antes, FAHClient no hace honor a la gestión de recursos de los contenedores, por lo que aunque yo le limite el número de CPUs a 5, si el nodo tiene 32, él va a pensar que tiene 32 CPUs para él (por ejemplo, desplegando 32 threads), cuando en realidad no es así.
Un caso similar ocurre con la memoria. Si le asigno 2 GB como límite, pero la máquina tiene 56 GB, el pensará que tiene 56 GB disponibles; y sin embargo Docker se encargará de que nunca reciba más de 2. ¿Consecuencia? Si necesita más de 2 GB de memoria el programa no podrá adaptarse y el rendimiento estará muy penalizado.
La solución ideal es que al igual que se hizo con la máquina virtual de Java en la versión 1.10, FAHClient tuviera en cuenta esto; pero mientras tanto podemos limitarle manualmente el uso de CPU y memoria mediante parámetros de la aplicación. Por eso en el manifiesto de Kubernetes podéis ver como los valores por defecto que facilitamos en MEM y CPUS coinciden con los limits: que hemos especificado más tarde.
Scripts: deploy-gpu-aks.bash
Este es el script encargado de implementar el cluster de AKS. Realiza las siguientes tareas:
- Crea el Azure AD Service Principal que vamos a necesitar.
- Genera un par de claves RSA pública y privada para el acceso root por SSH en los nodos del cluster.
- Escribe todo ello en el archivo
deploy-gpu-aks.parameters.json(en realidad, en una copia en la carpetaoputput/). Para ello hace uso extensivo del magnífico jq una utilidad de línea de comando de manipulación de datos JSON. - Comprueba si el grupo de recursos donde vamos a desplegar existe y en caso contrario lo crea.
- Y finalmente y de forma evidente, lanza el despliegue de la plantilla ARM con sus correspondientes parámetros.
Scripts: clean-gpu-aks.bash
No hay mucho que comentar aquí. Eliminamos el Azure AD Service Principal y el grupo de recursos donde hemos desplegado el cluster para dejar la suscripción de Azure en su estado original antes de desplegar nada. Evidentemente si previamente existía algo en el grupo de recursos, también será eliminado.
Como curiosidad, para asegurar que quien lanza el script sabe lo que está haciendo, este sólo funciona si le proporcionamos el parámetro --iknowwhatiamdoing.
Scripts: setup.bash
Este script no es que sea realmente necesario, pero la idea detrás de él es que todo lo comentado hasta ahora se pueda implementar de forma rápida sin haber hecho una lectura exhaustiva de las instrucciones y con una interfaz de usuario razonablemente amigable.
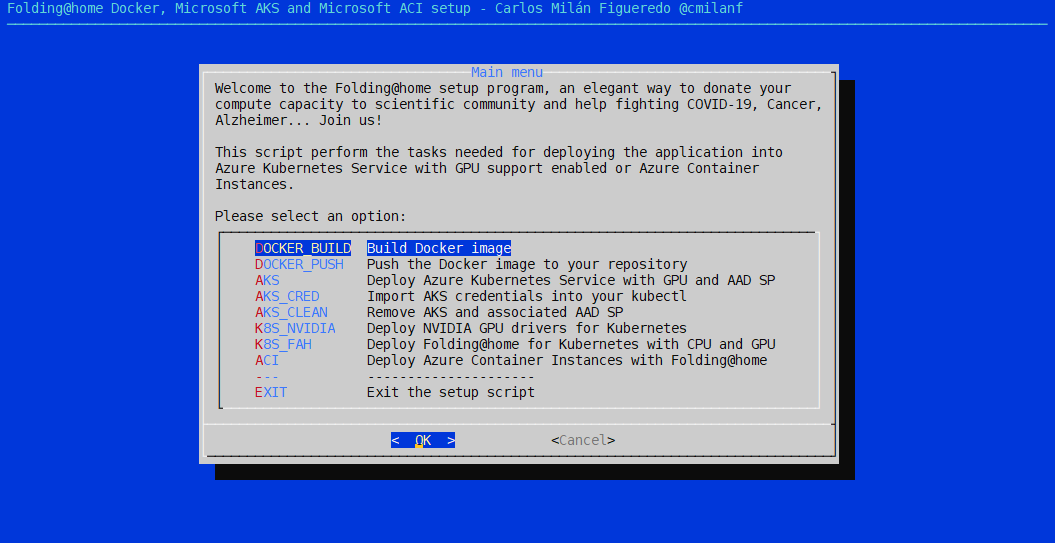
He creado la interfaz de usuario utilizando una utilidad tan arcana como versátil y elegante: dialog, que data de diciembre de 1993, con su última versión en marzo de 2001, con un listado de diferentes desarrolladores cuanto menos interesante. Sigue estando incluida en la mayoría de distribuciones de GNU/Linux.
Una de las grandes limitaciones de dialog es que no se puede copiar y pegar texto en sus formularios, y no quería imaginarme a un usuario escribiendo un Azure Subscription Id carácter a carácter. Para solverntarlo, a pesar de la interfaz de usuario, el script acepta parámetros para que valores como el Azure Subscription id o el nombre del grupo de recursos aparezcan ya por defecto en los formularios de la siguiente forma:
Un ejemplo de ejecución con parámetros sería:
./setup.bash -g fah -s edcad50b-44b2-443b-8a32-f4e6c0d26d78 -l westeurope
Cómo desplegarlo todo
Las instrucciones completas de implementación con multitud de capturas de pantalla se pueden ver en el README.md del repositorio de Github, pero como se encuentran en inglés, me voy a permitir reproducir los pasos en castellano:
Instalando pre-requisitos y ejecutando el setup
Se asume que los pasos se ejecutan desde una distribución de GNU/Linux desde una shell bash, siendo WSL también válido:
- Instala
gity clona el repositorio congit clone https://github.com/cmilanf/docker-foldingathome.git. - Instala Azure CLI en tu distribución.
- Instala kubectl.
- Instala las dependencias:
dialog,sed,jqyssh-keygen. Normalmente estan disponibles en el gestor de paquetes de tu distribución de GNU/Linux. - Inicia la sesión en Azure mediante
az login. - Haz un listado de las suscripciones disponibles con
az account list -o tabley selecciona en la que quieras tabajar conaz account set -s <subscription id>. Mantén el id a mano porque el setup lo pide explícitamente por seguridad. No queremos desplegar elementos y generar gasto en la suscripción equivocada ¿verdad? - Ejecuta el setup con
./setup.bash -g <Grupo de Recursos de Azure a utilizar o crear> -s <subscription id> -l <región>.
Hecho esto se te debería presentar en pantalla el menú principal de la utilidad. A partir de ahí, si quieremos implementar FAHClient mediante AKS:
- Echa un vistazo al archivo
arm/deploy-gpu-aks.parameters.jsony comprueba que esté a tu gusto. Recuerda que el Azure AD SP y la clave pública RSA de root las pone el script por tí. - Selecciona la opción AKS e introduce los datos que falten. Recuerda que si despliegas máquinas con GPU, estas tienen un coste notable.
- Cuando termines la implementación de AKS con éxito, selecciona AKS_CRED, que importará las credenciales de AKS en
kubectl. - Hecho eso estaremos preparados para instalar el plugin para la GPU de NVIDIA con la opción K8S_NVIDIA. Podemos comprobar que la instalación fue bien si aparece el recurso
nvidia.com/gpual hacer unkubectl describe node. - Finalmente desplegamos FAHClient con K8S_FAH.
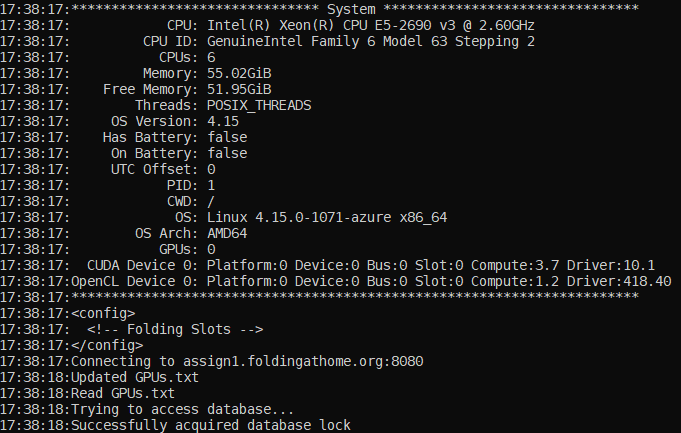
El resultado nos debe dejar ver lo siguiente con kubectl logs, donde podemos ver que nos ha detectado correctamente la GPU y... confirmamos que ve las CPUs y la memoria RAM de todo el nodo:
¿Y si lo hacemos por ACI? Mucho más sencillo, ya que sólo tenemos que seleccionar ACI en el menu, sin necesidad de seguir ningún paso anterior.
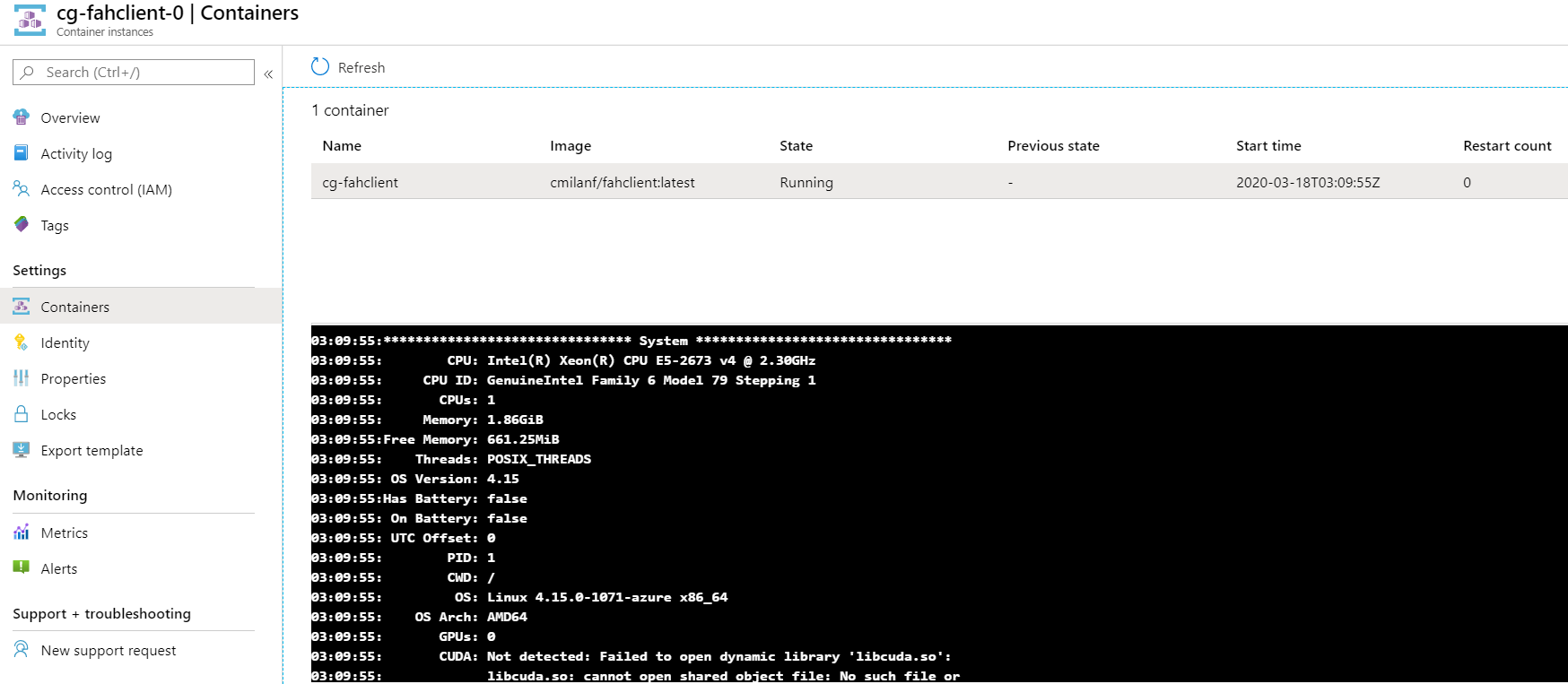
Conclusiones
Corren tiempos difíciles donde cualquier ayuda que podamos prestar para luchar contra la pandemia es poca. Conectar a los ciudadanos con la comunidad científica siempre ha sido históricamente un tema complicado, y si a eso le agregamos aspectos computacionales, más aún.
El proyecto Folding@home es una manera sencilla y directa de contribuir con la comunidad científica, donando capacidad de computación on-premises o bien del propio Azure a una causa que nos afecta a todos.
No quiero dejar de aprovechar estas líneas para dar las gracias a todos los colectivos profesionales que se están dejando la piel en la causa: médicos, enfermeros, investigadores, cuerpos y fuerzas de seguridad del estado, ejército, empleados de servicios esenciales como supermercados o banca, transportistas, productores... Y animar a los versados en las ciencias de la computación para pensar de qué forma podemos hacer algo por los demás y contribuir a la mejor de las causas.
¡Mucho ánimo a todos!